Ejecución en GPUs#
Las GPUs de Clementina tienen múltiples particularidades. En primer lugar, son GPUs de Intel y como tales usan el stack de software de Intel en lugar de CUDA (en el caso de NVIDIA) o ROCm/HIP (en el caso de AMD). En segundo lugar, las GPUs tienen una microarquitectura no tradicional que implica algunos cambios en su uso. Esta sección está orientada a aclarar algunas de las particularidades del hardware y el software, para poder garantizar un uso óptimo del equipo.
Especificaciones Intel GPU MAX 1550#
Arquitectura |
Xe-HPC |
|---|---|
Modelo |
Intel® Data Center GPU MAX 1550 |
Año de lanzamiento |
2023 |
Nombre en clave |
Ponte Vecchio (PVC) |
Tipo de GPU |
Discreta |
Caso de uso |
HPC |
Xe-Cores |
\(64 \times 2\) (\(64/\text{tile}\)) |
Vector Engines / Xe-Core |
8 |
# Vector Engines |
\(512 \times 2\) (\(512/\text{tile}\)) |
Hardware Threads / Vector Engine |
8 |
# Hardware Threads |
\(4096 \times 2\) (\(4096/\text{tile}\)) |
Matrix Engine (Soporte XMX/DPAS) |
Sí |
Soporte nativo doble precisión |
Sí |
# General Register Files / thread |
128 / 256 (regular mode / large register mode) |
Ancho de registro |
512 bits |
VRAM/memoria global |
128 GB (64/tile) |
Caché L3 |
2 x 192 MB |
Caché L1 / Xe-Core |
512 KB |
SLM / Xe-Core |
128 KB |
Máxima SLM/Work-Group |
128 KB |
Máximo tamaño Work-Group |
1024 |
Tamaños soportados de Sub-group |
16, 32 |
En cada nodo GPU de Clementina hay 4 GPUs interconectadas por Xe-Link, por lo que se disponen de \(4 \times 128=512 \text{GB}\) de VRAM, además de los 512 GB de RAM/HBM de las CPUs. A continuación se explica qué significan los términos específicos a Intel.
Arquitectura/jerarquía de las GPUs#
 Fuente: Intel ®
Fuente: Intel ®
{kind=link}
Las GPUs se organizan de acuerdo a la arquitectura Xe-HPC de Intel. Esto quiere decir que están organizadas jerárquicamente en los siguientes componentes:
Vector engine#
Un vector engine es la unidad fundamental de cómputo de la GPU. Esencialmente es una unidad aritmético-lógica (ALU) SIMD (Single Instruction Multiple Data) con múltiples threads. Cada Vector Engine tiene 8 threads en hardware, y cada uno de ellos puede ejecutar 16 o 32 instrucciones SIMD, de acuerdo al tipo de dato. Los tipos de dato pposibles son FP64, FP32, FP16, INT64, BF16, INT32, INT16, INT8, etc. Cada thread tiene a su vez un register file de alto ancho de banda, de 512 bits de ancho en el caso de las Intel PVC. Adicionalmente, hay unidades análogas a los vector engines específicamente para operaciones matriciales: estas unidades se denominan Xe Matrix Extensions o XMXs.
Xe-Core#
Los vector engines se agrupan (de a 8 en el caso de las GPU MAX 1550) en Xe-Cores. Cada Xe-core consiste en 8 vector engines y 8 XMXs, con una memoria caché L1 accesible por todos los vector engines. En nuestro caso, la L1 es de 512 kB por cada Xe-core y es la memoria de acceso más rápido por fuera de los registros de los vector engines en sí.
Xe-Stack (o tile)#
Los Xe-cores en sí se agrupan en slices vinculadas a través de una Xe Infinity fabric, que actúa como L2 para compartir memoria entre distintas slices de Xe-cores. Además, todas las unidades Junto a unidades de ray tracing, controladores de memoria, media engines (para HW decoding/encoding), etc. Cada stack/tile tiene su propia conexión al lane de PCIe y su propia conexión al lane de Xe-Link, la interfaz de baja latencia que interconecta las GPUs. Es decir, cada stack/tile ya es una GPU en el sentido tradicional de la palabra, pero no es la unidad jerárquica superior de la GPU.
GPU#
Críticamente, la GPU en su totalidad consiste en dos tiles/Xe-stacks por una conexión especial de stack a stack de menor latencia. Es decir que, aunque tienen menor latencia que la conexión con otra GPU, no comparten directamente el mismo nivel de caché. Esto quiere decir que considerar a la GPU como una única unidad de cómputo puede traer problemas, al igual que solamente considerarlas como unidades separadas.
Visibilidad de las GPUs#
Al tener en cuenta que las GPUs consisten en múltiples tiles, y que no obedecen a una arquitectura completamente tradicional, es importante entonces determinar cómo se exponen a nivel usuario para poder usarlas óptimamente.
La jerarquía y exposición de los dispositivos puede controlarse a través de de distintas variables de entorno. Como se indica en la imagen, la capa más baja de abstracción es el uso de la API Level Zero de Intel. Level Zero regula directamente el uso del driver de la GPU y regula la visibilidad de los dispositivos a cualquier entorno de ejecución o aplicación. Es decir, al fijar la visibilidad en Level Zero ninguna aplicación va a poder ver los dispositivos ocultos. También es posible no modificar la exposición de Level Zero y simplemente elegir desde el entorno de ejecución cómo se desea acceder a los dispositivos. OpenCL, OpenMP y SYCL son los principales modelos de programación y entornos de ejecución nativos para las GPUs de Intel.
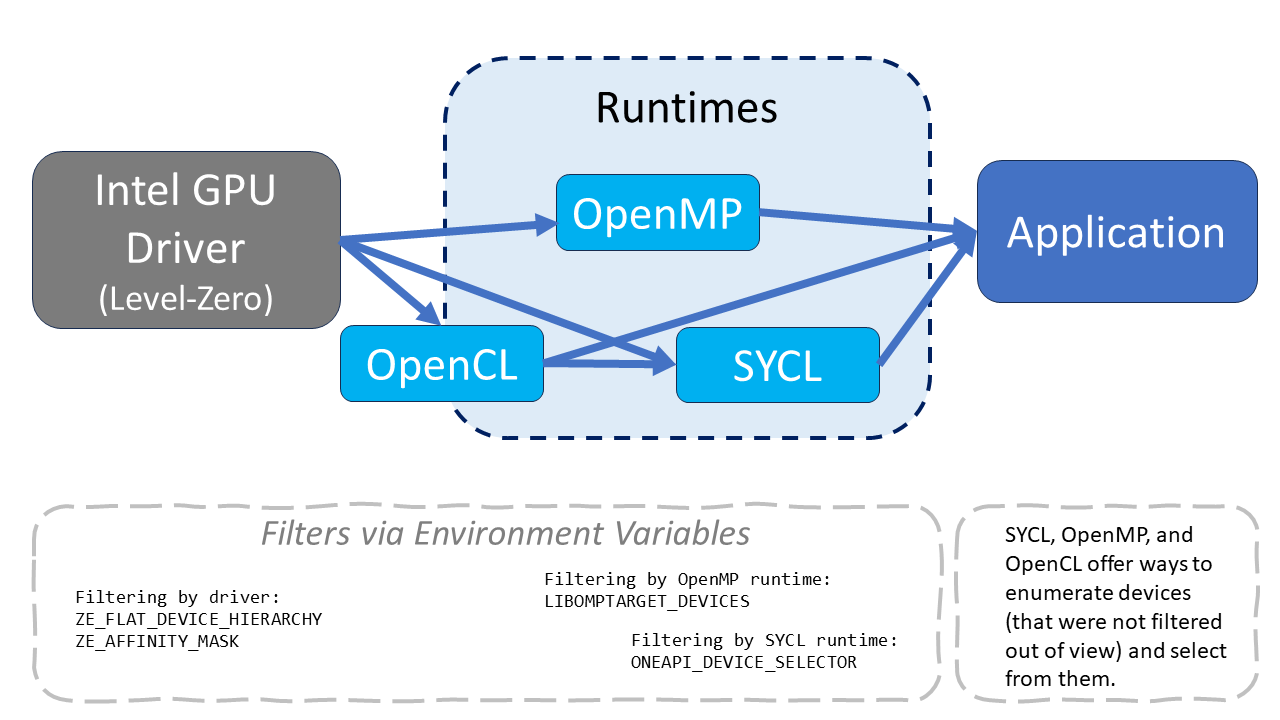 Fuente: Flattening GPU Tile Hierarchy
Fuente: Flattening GPU Tile Hierarchy
Level Zero#
ZE_FLAT_DEVICE_HIERARCHY#
La variable de entorno ZE_FLAT_DEVICE_HIERARCHY controla si lo que el entorno de ejecución considera una GPU es cada GPU de dos tiles, o cada tile en sí. Esto se corresponde con los valores COMPOSITE y FLAT, respectivamente.
Fijar export ZE_FLAT_DEVICE_HIERARCHY=FLAT expone cada tile como un dispositivo separado. El modo FLAT es el valor por defecto y se ajusta mejor a la no uniformidad de las GPUs, o a los programas optimizados para GPUs de una única tile. Esto se debe a que, para programas pensados para múltiples GPUs de una única tile, agregar la asimetría de la comunicación entre tiles (ver la sección de jerarquías más arriba) probablemente reduciría la performance.
Como ejemplo ilustrativo, en modo FLAT se deberían poder listar los dispositivos de cada nodo con sycl-ls de la siguiente manera:
module purge
module load stages/2026
module load oneapi/2025.1.0
ZE_FLAT_DEVICE_HIERARCHY=FLAT sycl-ls
[level_zero:gpu][level_zero:0] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:1] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:2] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:3] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:4] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:5] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:6] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:7] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[opencl:gpu][opencl:0] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:1] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:2] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:3] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:4] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:5] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:6] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:7] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
Cada línea indica un dispositivo, visible desde la API de Level Zero u OpenCL, el modelo de GPU y la versión correspondiente de los drivers asociados a cada API. Como los nodos tienen 4 GPUs de 2 tiles, hay en total 8 dispositivos asociados. Sin embargo, si esto se corre a través de un job de Slurm (sbatch/srun --gpus=4), se obtiene
ZE_FLAT_DEVICE_HIERARCHY=FLAT sycl-ls
[level_zero:gpu][level_zero:0] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:1] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:2] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:3] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[opencl:gpu][opencl:0] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:1] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:2] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:3] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
Esto es un problema de la integración con Slurm: Slurm fija incorrectamente la variable ZE_AFFINITY_MASK, y oculta los dispositivos restantes. Crucialmente, los 4 dispositivos restantes siguen siendo una única tile, por lo que efectivamente por defecto se exponen 4 «subGPUs» de 64GB en lugar de 8. Esto es un comportamiento erróneo y está en proceso de corregirse, por lo pronto se puede ejecutar unset ZE_AFFINITY_MASK o fijar la máscara como se detalla a continuación.
El modo COMPOSITE (export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE), por el contrario, expone cada GPU como un dispositivo y cada tile como un subdevice asociado. Esto funciona mejor para programas de una única GPU, pero puede nuevamente traer problemas en la distribución uniforme del trabajo entre tiles. Es posible superar estas dificultades regulando el acceso a los subdispositivos desde el entorno de ejecución o usando el modo FLAT.
Retomando el mismo ejemplo ilustrativo, correr sycl-ls en un nodo resulta en:
ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE sycl-ls
[level_zero:gpu][level_zero:0] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:1] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:2] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[level_zero:gpu][level_zero:3] Intel(R) oneAPI Unified Runtime over Level-Zero, Intel(R) Data Center GPU Max 1550 12.60.7 [1.6.33578+38]
[opencl:gpu][opencl:0] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:1] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:2] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
[opencl:gpu][opencl:3] Intel(R) OpenCL Graphics, Intel(R) Data Center GPU Max 1550 OpenCL 3.0 NEO [25.18.33578]
Aunque el resultado parece igual al anterior, en este caso cada dispositivo es una GPU de dos tiles con 128GB. Actualmente, este es el valor más deseable para usar las GPUs enteras. El ejemplo de envío de LAMMPS ilustra lo ambiguo de la notación: como la variable de entorno está en modo COMPOSITE, cada GPU se expone como un dispositivo. Pero, como el backend de LAMMPS está escrito en OpenCL enfocado a subdevices, considera los 8 subdispositivos totales.
ZE_AFFINITY_MASK#
Por defecto, una vez fija la variable ZE_FLAT_DEVICE_HIERARCHY, se exponen todos los devices o subdevices disponibles. Cuando se quieren ver menos dispositivos, se usa una affinity mask.
En modo COMPOSITE, se indica una lista de valores compuestos por dispositivo y tile. Por ejemplo ZE_AFFINITY_MASK=0.0,0.1 representa la tile 0 y la tile 1 del dispositivo 0. Si solo se expone una tile del dispositivo, cada tile funciona como un dispositvo separado. Si se incluyen ambas tiles del mismodispositivo, son automáticamente combinadas en un único dispositivo.
En modo FLAT, simplemente se designa cada tile. Por ejemplo, ZE_AFFINITY_MASK=1,3,5,7 expone solo la segunda tile de cada dispositivo, mientras que ZE_AFFINITY_MASK=0,2,4,6 expone la primera.
SYCL/OpenMP#
Si, en lugar de usar la API de Level Zero, se desea ajustar el envío a dispositivos desde el entorno de ejecución, puede realizarse a través de otras variables de entorno para los modelos de programación adecuados.
En el caso de SYCL, la selección de dispositivos puede hacerse de manera similar a cómo se realiza en modo COMPOSITE, con la variable de entorno ONEAPI_DEVICE_SELECTOR. Por ejemplo, para seleccionar todos los dispositivos usando Level Zero como backend, se usa ONEAPI_DEVICE_SELECTOR=level_zero:*.*. Si se deseara usar solo el dispositivo 0, se especifica en el primer campo con ONEAPI_DEVICE_SELECTOR=level_zero:0.*. Si solo se deseara usar la primera tile, se usa ONEAPI_DEVICE_SELECTOR=level_zero:0.0. Puede observarse un detalle del comportamiento de esta variable en la documentación.
Para OpenMP, la visibilidad de las jerarquías puede realizarse a través de la variable de entorno LIBOMPTARGET_DEVICES, cuyos valores posibles son:
DEVICE: el valor por defecto, en el cual solo los dispositivos de mayor jerarquía se listan como dispositivos de OpenMP.SUBDEVICE: cada subdispositivo es un dispositivo de OpenMP.ALL: se exponen tanto dispositivos como subdispositivos como dispositivos de OpenMP