LAMMPS#
![]()
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) es un programa de simulación de dinámica molecular clásica, que provee múltiples paquetes para simular una amplia gama de campos de fuerza, condiciones de contorno, etc.
Versiones instaladas#
Actualmente existen dos versiones de LAMMPS instaladas en ClementinaXXI.
lammps/2024-Aug-opencl: Versión estable29Aug2024. Está compilada con el paquete GPU (backend de OpenCL) para soportar las GPUs Intel PVC que están presentes en los nodos de cómputo; además del paquete INTEL para poder hacer uso correcto de las extensiones de AVX512 de los procesadores CPU Max.lammps/2026-Feb-symmetrix-xpu: Versión testing de la release11Feb2026adaptada para utilizar el software Symmetrix.
lammps/2024-Aug-opencl#
A continuación, se listan todos los paquetes instalados en esta versión:
AMOEBA |
ASPHERE |
BOCS |
BODY |
BPM |
BROWNIAN |
CG-DNA |
CG-SPICA |
CLASS2 |
COLLOID |
COLVARS |
COMPRESS |
CORESHELL |
DIELECTRIC |
DIFFRACTION |
DIPOLE |
DPD-BASIC |
DPD-MESO |
DPD-REACT |
DPD-SMOOTH |
DRUDE |
EFF |
ELECTRODE |
EXTRA-COMMAND |
EXTRA-COMPUTE |
EXTRA-DUMP |
EXTRA-FIX |
EXTRA-MOLECULE |
EXTRA-PAIR |
FEP |
GPU |
GRANULAR |
INTEL |
INTERLAYER |
KSPACE |
LEPTON |
MACHDYN |
MANYBODY |
MC |
MEAM |
MESONT |
MISC |
ML-IAP |
ML-POD |
ML-SNAP |
ML-UF3 |
MOFFF |
MOLECULE |
OPENMP |
OPT |
ORIENT |
PERI |
PHONON |
PLUGIN |
POEMS |
QEQ |
REACTION |
REAXFF |
REPLICA |
RIGID |
SHOCK |
SPH |
SPIN |
SRD |
TALLY |
UEF |
VORONOI |
YAFF |
El módulo de LAMMPS se carga con
module load lammps/2024-Aug-opencl
Al cargarse se puede ejecutar LAMMPS normalmente con el ejecutable lmp en conjunto con mpirun.
Si un usuario requiere de otra versión específica, se recomienda seguir las instrucciones al final de esta página o usar spack para automatizar la compilación.
Performance#
Advertencia
Antes de realizar pruebas de escalabilidad, verifique que el trabajo de prueba corra muy rápidamente, de otra forma el mismo proceso de hacer pruebas va a consumir horas de cómputo de su cuenta.
Se recomienda fuertemente hacer pruebas de escalabilidad en un job de termalización con número de pasos temporales reducidos, a fin de realizar pruebas rápidamente y no consumir demasiado tiempo de cómputo.
La documentación del paquete GPU indica cómo incorporar las directivas de GPU a los styles correspondientes y qué heurísticas seguir para alcanzar mejor performance.
Algunos de los aspectos más importantes a destacar son:
El switch
-sf gpuaplica automáticamente los styles de GPU a un input regular de LAMMPS, y el switch-pk <número>determina la cantidad de GPUs a utilizar por nodo. Por ejemplo,mpirun -np 48 lmp -sf gpu -pk gpu 4 -in in.scriptejecuta el scriptin.scripten un nodo con 48 ranks de MPI y con 4 GPUs.El comportamiento por defecto del paquete GPU es desactivar la flag de las interacciones a pares.
El paralelismo de MPI típicamente es mejor que el paralelismo de OpenMP, salvo en algunos casos como potenciales de 3 cuerpos.
Usar múltiples ranks de MPI por GPU (2-10) da la mejor performance, usar demasiados agrega overhead y resulta en peor performance.
En caso de pocas partículas puede ser más eficiente reducir la cantidad de ranks de MPI por GPU.
La documentación oficial contiene más información adicional que puede resultar relevante.
Véase también:
Running LAMMPS in HPC Systems (la instalación actualmente no tiene soporte para Kokkos)
Ejemplo de escalabilidad#
Nota
Ejemplo realizado con el módulo lammps/2024-Aug-opencl
A continuación, se presenta una prueba de escalabilidad básica para un Lennard-Jones para ~1000000 de partículas, siguiendo los criterios anteriores.
En primer lugar, se determinó que el valor óptimo para el ejemplo era de 6 ranks de MPI por cada GPU, tomando una sola GPU y variando la cantidad con un for loop sencillo como
export OMP_NUM_THREADS=1 # En este caso se mantienen los threads de OpenMP fijos en 1
for i in {1..12}; do
mpirun -n $i lmp -in lennard-jones.in > out_$i
done;
A partir de este valor óptimo se utilizaron 24 cores por nodo para realizar pruebas de escalabilidad a más nodos: subutilizar la cantidad de cores de un nodo igual cuenta para el IPAC como usar todos los 64, pero es preferible si con 24 es más rápido.
Se pueden observar los resultados para performance y eficiencia en la siguiente figura:
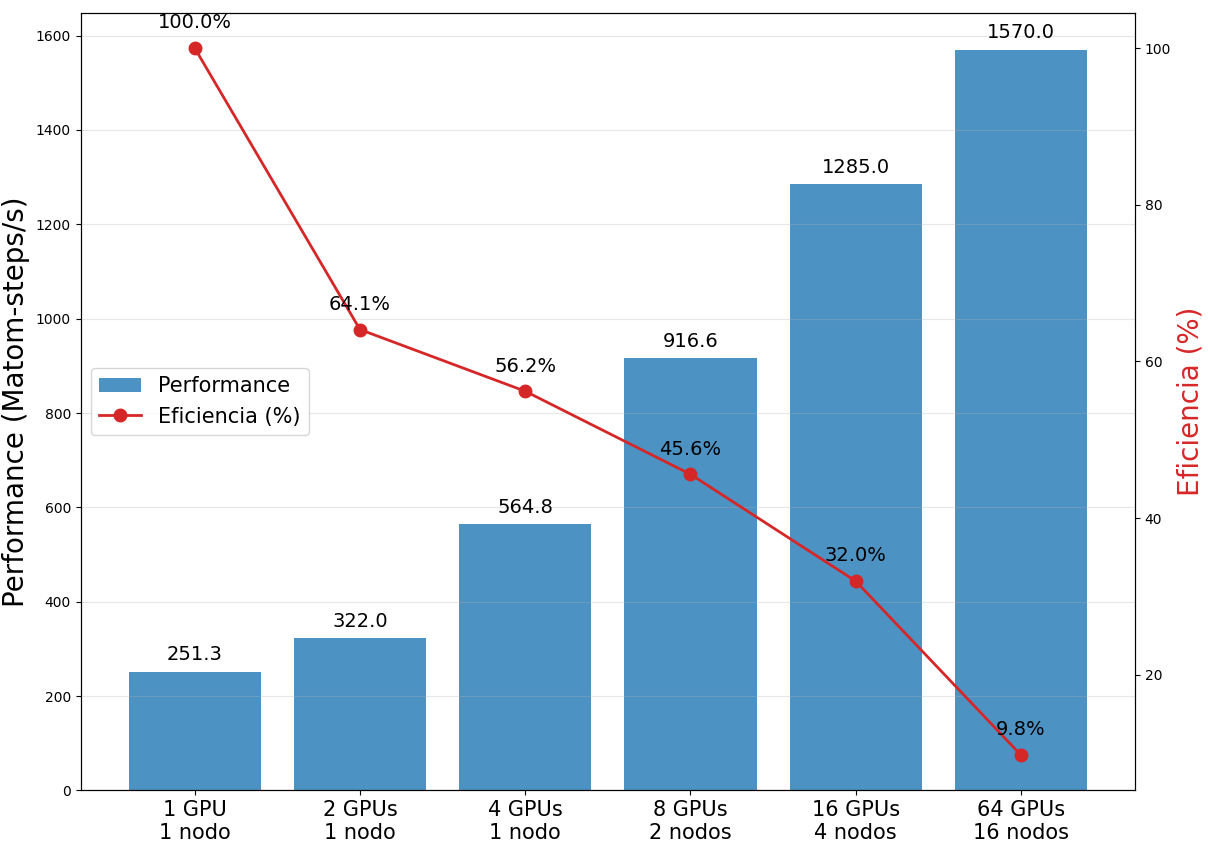
Advertencia
Las pruebas de escalabilidad que se muestran a continuación están desactualizadas, deberían ser aproximadamente el doble en performance. Esto se debe a la variable agregada en los scripts de ejemplo, que permite exponer la GPU entera en lugar de una única tile, como se documenta aquí. Estamos trabajando en agregar benchmarks para casos más relevantes y actualizados.
A partir de esto puede ser conveniente considerar si es mejor correr en pocos nodos con alta eficiencia o muchos nodos con baja eficiencia.
Ejemplos de envío#
Advertencia
Estos ejemplos están armados para el caso en el que 6 ranks de MPI por GPU son óptimos, y desperdiciaría muchos cores de CPU y horas cómputo en el caso en que no lo sea. Se recomienda fuertemente hacer una prueba de escalabilidad y determinar el valor óptimo para la carga particular.
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --partition=gpunode
#SBATCH --nodes=1
#SBATCH --tasks-per-node=64
#SBATCH --gpus=4
#SBATCH --exclusive ## Para tomar el nodo por completo
#SBATCH --output=output_%j.txt
#SBATCH --error=error_%j.txt
cd $SLURM_SUBMIT_DIR
module purge
module load lammps/2024-Aug-opencl
export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE
mpirun -np 48 lmp -sf gpu -pk gpu 8 -in <archivo de input>
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --partition=gpunode
#SBATCH --nodes=2
#SBATCH --ntasks=48
#SBATCH --gpus-per-node=4
#SBATCH --tasks-per-node=24
#SBATCH --exclusive ## Para tomar el nodo por completo
#SBATCH --output=output_%j.txt
#SBATCH --error=error_%j.txt
scontrol show hostnames $SLURM_NODELIST | awk '{print $1 " slots=24"}' > nodes.dat
cd $SLURM_SUBMIT_DIR
module purge
module load lammps/2024-Aug-opencl
export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE
mpirun --hostfile nodes.dat lmp -sf gpu -pk gpu 8 -in <archivo de input>
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --partition=gpunode
#SBATCH --nodes=4
#SBATCH --ntasks=96
#SBATCH --gpus-per-node=4
#SBATCH --tasks-per-node=24
#SBATCH --exclusive ## Para tomar el nodo por completo
#SBATCH --output=output_%j.txt
#SBATCH --error=error_%j.txt
scontrol show hostnames $SLURM_NODELIST | awk '{print $1 " slots=24"}' > nodes.dat
cd $SLURM_SUBMIT_DIR
module purge
module load lammps/2024-Aug-opencl
export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE
mpirun --hostfile nodes.dat lmp -sf gpu -pk gpu 8 -in <archivo de input>
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --partition=gpunode
#SBATCH --nodes=16
#SBATCH --ntasks=384
#SBATCH --gpus-per-node=4
#SBATCH --tasks-per-node=24
#SBATCH --exclusive ## Para tomar el nodo por completo
#SBATCH --output=output_%j.txt
#SBATCH --error=error_%j.txt
scontrol show hostnames $SLURM_NODELIST | awk '{print $1 " slots=24"}' > nodes.dat
cd $SLURM_SUBMIT_DIR
module purge
module load lammps/2024-Aug-opencl
export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE
mpirun --hostfile nodes.dat lmp -sf gpu -pk gpu 8 -in <archivo de input>
Para una explicación detallada del por qué de las variables de entorno y el uso de 8 «GPUs» en lugar de 4, véase la sección correspondiente de la documentación.
Symmetrix#
Utilizamos Symmetrix ya que implementa una biblioteca de operaciones de equivarianza que es compatible con la arquitectura de GPUs de ClementinaXXI. MACE ofrece dos opciones para realizar inferencia en LAMMPS:
Mace in LAMMPS: La llamamos informalmente “legacy”, con la cual encontramos limitaciones en el uso de vRAM para escalar simulaciones de más de 1000 átomos. Esta depende de
e3nn, una biblioteca que no está disponible para nuestra arquitectura.Mace in LAMMPS with ML-IAP: La versión más performante, pero que depende de la biblioteca
cuEquivariance, solo disponible para arquitectura CUDA.
In addition to the native PyTorch implementations of the MACE-OFF23 models, we also report results for optimized implementations leveraging custom C++, CUDA, and/or Kokkos code. One optimized variant incorporates custom CUDA kernels which are packaged as a standalone, inference-only library, cuda mace. Another pure-C++ implementation, as well as a Kokkos implementation, will be made available as part of the symmetrix library.
—D. P. Kovács, J. H. Moore, N. J. Browning, I. Batatia, J. T. Horton, Y. Pu, V. Kapil, W. C. Witt, I.-B. Magdău, D. J. Cole, G. Csányi MACE-OFF: Short-Range Transferable Machine Learning Force Fields for Organic Molecules, Journal of the American Chemical Society 147, 17598 (2025).
Convertir modelo#
El paquete de Python de symmetrix se encuentra presente en el enviroment ubicado en /data/shared/apps/envs/symmetrix-xpu.
Por ejemplo, para convertir un modelo de mace para symmetrix enfocado en H y O:
micromamba activate /data/shared/apps/envs/symmetrix-xpu
symmetrix_extract_mace my-mace.model --atomic-numbers 1 8
conda activate /data/shared/apps/envs/symmetrix-xpu
symmetrix_extract_mace my-mace.model --atomic-numbers 1 8
Esto genera un archivo .json desde el modelo basado en PyTorch. El resultado va a ser my-mace-1-8.json y solo es compatible con H y O.
Utilizar modelo#
En el input de LAMMPS, hay que especificar pair_style y pair_coeff:
pair_style symmetrix/mace
pair_coeff * * my-mace-1-8.json H O
Una vez preparado el input, y convertido el modelo, podemos realizar una corrida de prueba:
#!/bin/bash
#SBATCH --job-name=symmetrix
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
#SBATCH --nodes=1
#SBATCH --gres=gpu:1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=1
#SBATCH --partition=testing
#SBATCH --time=00-00:20:00
module purge
module load lammps/2026-Feb-symmetrix-xpu
eval "$(micromamba shell hook --shell bash)"
micromamba activate /data/shared/apps/envs/symmetrix-xpu
mpirun -np 1 lmp -k on g 1 -sf kk -pk kokkos newton on neigh half -i input.lammps
Simular con ManyGPU#
Cada GPU de ClementinaXXI tiene 128GB de memoria. En caso de que la simulación requiera una cantidad de memoria mayor, podemos aplicar una estrategia de ManyGPU, donde una simulación utiliza las 4 GPUs de un nodo.
Para eso, son necesarios algunos scripts adicionales.
En el directorio de la simulación, generar el archivo bind.sh con el siguiente contenido:
#!/bin/bash
# Selecciona una GPU física basándose en el RANK local de MPI
# Funciona con Intel MPI (IPI_LOCALRANKID)
export ONEAPI_DEVICE_SELECTOR=level_zero:${MPI_LOCALRANKID:-0}
exec "$@"
Opcionalmente, también crear el archivo monitor_gpu.sh, muy útil para monitorear el uso de memoria en cada GPU.
#!/bin/bash
# monitor_gpu.sh: Monitorea la memoria en las 4 GPUs
GPUS=$(xpu-smi discovery | grep "| [0-9]" | awk '{print $2}' | sort -u | xargs)
if [ -z "$GPUS" ]; then
GPUS="0 1 2 3"
fi
INTERVAL=${1:-10}
HEADER="Time"
for i in $GPUS; do
HEADER="$HEADER | GPU$i"
done
echo "$HEADER"
echo "------------------------------------------------"
while true; do
TIMESTAMP=$(date +%H:%M:%S)
output_line="$TIMESTAMP"
for i in $GPUS; do
LINE=$(xpu-smi stats -d $i 2>/dev/null | grep "Memory Used")
if [ -n "$LINE" ]; then
SUM=$(echo "$LINE" | awk -F'[:;]' '{sum=0; for(j=2; j<=NF; j+=2) { val=$j; gsub(/[^0-9]/,"",val); if(val!="") sum+=val } print sum}')
else
SUM=0
fi
output_line="$output_line | ${SUM:-0}"
done
echo "$output_line"
sleep $INTERVAL
done
Basar el script de slurm en el siguiente submit.sh:
#!/bin/bash
#SBATCH --job-name=lammps_4gpu
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
#SBATCH --nodes=1
#SBATCH --gres=gpu:4
#SBATCH --ntasks-per-node=4
#SBATCH --cpus-per-task=8
#SBATCH --partition=testing
#SBATCH --time=00-00:20:00
# Cargar módulo y enviroment
module purge
module load lammps/2026-Feb-symmetrix-xpu
eval "$(micromamba shell hook --shell bash)"
micromamba activate /data/shared/apps/envs/symmetrix-xpu
# Optimización para GPUs Intel GPUs y MPI
export I_MPI_OFFLOAD=1
export ZE_ENABLE_PCI_ID_DEVICE_ORDER=1
# Usamos modo COMPOSITE para no tratar a cada GPU como Tiles
export ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE
# Monitoreamos uso de GPU en el background
chmod +x monitor_gpu.sh
./monitor_gpu.sh 10 > memory_usage.txt &
MONITOR_PID=$!
# Correr LAMMPS con 4 GPUs usando mpirun y el script de binding
chmod +x bind.sh
mpirun -np 4 ./bind.sh lmp -k on g 1 -sf kk -pk kokkos newton on neigh half -i input.lammps -log log.lammps
# Terminar monitoreo
kill $MONITOR_PID
sleep 2
Asegúrese de que los scripts tienen permiso de ejecución:
chmod +x bind.sh monitor_gpu.sh
En el directorio de lanzamiento, debería tener los siguientes archivos:
input.lammps: Parámetros de simulación.interfase.lammps-data: Estructura atómica.my-mace-1-8.json: Archivo de potencial de MACE convertido a json.bind.sh: Script asistente para mapear ranks de MPI a GPUs.monitor_gpu.sh: Background script para monitorear el uso de VRAM en todas las gpus-per-node.submit.sh: Slurm batch script con opciones de enviroment.
Una vez hecho esto, puede enviar el job utilizando sbatch submit.sh.
Compilación de otras versiones#
En caso de ser necesaria una versión específica de LAMMPS, se pueden seguir los siguientes pasos dentro de un nodo de cómputo (ya sea en modo batch o interactivo):
## En el directorio de los fuentes luego de desempaquetar el .tar.gz
module load intel openmpi4 cmake
mkdir build && cd build
export CC=icx
export FC=ifx
export CXX=icpx
cmake -DCMAKE_CXX_FLAGS="-msse4.1 -msse3" -DCMAKE_C_FLAGS="-msse4.1 -msse3" -D PKG_INTEL=yes -D PKG_GPU=yes -D GPU_API=opencl -D FFT=MKL ../cmake/ -C ../cmake/presets/most.cmake
cmake --build . -j64
Sobre la configuración de cmake se pueden agregar otras opciones, los presets agregan la mayoría de los paquetes detallados anteriormente.