Amber#
Amber es una suite de simulación biomolecular, que reúne modelos de fuerzas entre biomoléculas y modelos de dinámica molecular. Amber consiste en dos paquetes: Amber y AmberTools.
Versiones instaladas#
Actualmente hay dos versiones instaladas:
Amber24 (con AmberTools24): Compilada para CPU con GCC 13 + OpenMPI 5. Incluye la extensión de Python y los paquetes habilitados por defecto.
Amber20 - Patch de SYCL: Versión experimental compilada para GPUs Intel Max 1550(que no tienen soporte para CUDA), con Intel OneAPI 2024 y OpenMPI 5. Incluye un set de paquetes mínimos
El módulo de Amber24 puede cargarse con:
module load amber/24
(Al cargarse se puede ejecutar pmemd o pmemd.MPI en conjunto con mpirun)
El módulo de Amber20-SYCL puede cargarse con:
module load amber/20-sycl
(Al cargarse se puede ejecutar pmemd.sycl_SPFP, pmemd.sycl_DPFP, pmemd.sycl_SPFP.MPI y pmemd.sycl_DPFP.MPI, más abajo se explica cómo utilizarlos)
Ambos módulos reemplazan la funcionalidad de ejecutar source amber.sh, por lo que no es necesario ejecutarlo.
Limitaciones de la versión GPU#
La versión de Amber20 compilada para GPUs tiene varias limitaciones con respecto a los tipos de cálculo que se pueden correr. En particular, solo soporta actualmente simulaciones de Particle Mesh Ewald en los ensambles con NVE, NVT y NPT constantes. Con esas restricciones, se encuentran habilitados:
Termostatos de Berendsen, Andersen y Langevin
Barostatos de Berendsen y Monte Carlo
Acoplamiento de presión isotrópica, anisotrópica y semiisotrópica
Dinámica molecular acelerada
La mayoría de las condiciones de vínculo de tipo NMR
Reparticionado de masa de hidrógeno
Potenciales de fuerza de CHARMM y Amber
Funcionalidades adicionales (p.ej. simulaciones generalizadas de Born) están en desarrollo y es posible que sean agregadas en la próxima release de Amber-SYCL, planeada para fines de 2025.
Performance de la versión GPU#
Las GPUs Intel GPU Max 1550 están divididas en 2 tiles, subunidades dentro de una misma GPU que pueden comunicarse entre sí con alto rendimiento. Cada nodo con GPU tiene 4 GPUs y, por lo tanto, 8 tiles. Amber20-SYCL está paralelizado para usar hasta 2 tiles por trabajo, es decir 1 GPU por vez.
La performance en 1 y 2 tiles puede observarse en la siguiente figura, tomada de un poster del SDSC:
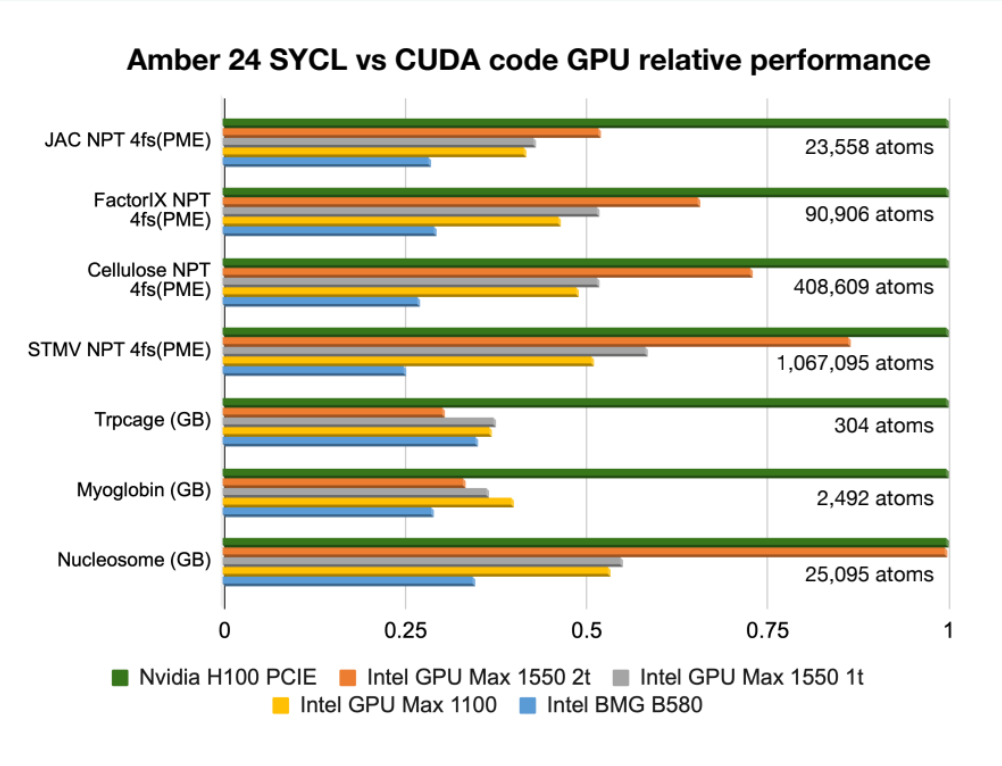
Es importante notar que la performance de la versión en SYCL suele ser inferior a la versión en CUDA, y difiere significativamente de acuerdo al tipo de cálculo y cantidad de partículas. La diferencia en performance entre 1 y 2 tiles también.
Ejemplos de envío#
Advertencia
El acceso a múltiples tiles no se encuentra funcional en Slurm actualmente (26/09/2025), estamos trabajando para habilitarlo lo más pronto posible
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --output=output_%j.txt
#SBATCH --error=error_%j.txt
#SBATCH --nodes=1
#SBATCH --ntasks=64
#SBATCH --ntasks-per-node=64
#SBATCH --partition=batch
#SBATCH --exclusive
module purge
module load amber/24
mpirun pmemd.MPI -O -i md.in -o md.out -p example.prmtop -c eq.crd -r rex.crd -x md.traj -inf mdinfo
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=4
#SBATCH --gres=gpu:1
#SBATCH --partition=gpunode
#SBATCH --output=clementina%j.log
#SBATCH --error=clementina%j.err
module purge
module load amber/20-sycl
export SYCL_CACHE_PERSISTENT=1
export SYCL_PI_LEVEL_ZERO_USM_ALLOCATOR="1;1G;host:1G,4,64K;device:1G,4,64K;"
export I_MPI_OFFLOAD=1
export I_MPI_OFFLOAD_IPC=0
export I_MPI_OFFLOAD_CELL_LIST=0,1 # <<< TILE 0 e TILE 1 �~@~T ESSENCIAL!
export I_MPI_OFFLOAD_L0_D2D_ENGINE_TYPE=1
mpirun -np 1 pmemd.sycl_SPFP.MPI -O \
-i input.mdin \
-c rest.rst \
-p params.parm \
-r rst.rst \
-o out.out \
-x nc.nc \
-inf mdinfo
#!/bin/bash
#SBATCH --job-name=<nombre del job>
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=4
#SBATCH --gres=gpu:2
#SBATCH --partition=gpunode
#SBATCH --output=clementina%j.log
#SBATCH --error=clementina%j.err
module purge
module load amber/20-sycl
export SYCL_CACHE_PERSISTENT=1
export SYCL_PI_LEVEL_ZERO_USM_ALLOCATOR="1;1G;host:1G,4,64K;device:1G,4,64K;"
export I_MPI_OFFLOAD=1
export I_MPI_OFFLOAD_IPC=0
export I_MPI_OFFLOAD_CELL_LIST=0,1 # <<< TILE 0 e TILE 1 �~@~T ESSENCIAL!
export I_MPI_OFFLOAD_L0_D2D_ENGINE_TYPE=1
mpirun -np 2 pmemd.sycl_SPFP.MPI -O \
-i input.mdin \
-c rest.rst \
-p params.parm \
-r rst.rst \
-o out.out \
-x nc.nc \
-inf mdinfo
Los ejecutables tienen una variante SPFP para precisión simple y DPFP para precisión doble.